Please join us congratulating our senior student Ying Nie, who is currently an undergraduate majoring in computer science as well as a research assistant in the GeoDS Lab under Prof. Song Gao’s mentorship, just got the UW-Madison “Hilldale Undergraduate/Faculty Research Fellowship” and was awarded in the 2024 Chancellor’s Undergraduate Awards Ceremony!
The awarded research project is: Large Language Model for Intelligent Spatial Analysis Workflow Construction
Our GeoDS lab’s students and alumni recently attended the American Association of Geographers (AAG) 2024 Annual Meeting held in Honolulu, HI. It was a great reunion for the GeoDS family at the conference!
Geospatial Artificial Intelligence (GeoAI) is a rapidly evolving interdisciplinary field that integrates geospatial studies with AI advancements. In this webinar editors and authors of the recently published GeoAI Handbook discuss the fundamental concepts, methods, applications, and perspectives of GeoAI. The GeoAI Handbook is an excellent resource for educators, students, practitioners and decision-makers who are interested in utilizing AI technologies in a geospatial context.
Schedule:
20 mins: Round-table Q&A about the GeoAI Handbook: Maria Antonia Brovelli, Andrea Manara, and Song Gao
10 mins: Chapter 5: GeoAI for Spatial Image Processing: Wenwen Li and Samantha Arundel
10 mins: Chapter 7: Intelligent Spatial Prediction and Interpolation Methods: Di Zhu
10 mins: Chapter 10: Spatial Cross-Validation for GeoAI: Yingjie Hu
10 mins: Wrap-up
The GeoAI advancements provide promising solutions to address some of the United Nations SDGs but also pose concerns. For example, Chapter 3 presents some of the fundamental assumptions and principles that could form the philosophical foundation of GeoAI and spatial data science. It highlights the sustainability issue for training GeoAI and foundation models that could cause substantial electricity energy and resource consumptions and generate equivalent carbon emissions. Therefore, we need to call for Green AI for achieving the SDG-13: Climate Action. Chapters 13 and 14 discuss existing and prospective GeoAI tools to support humanitarian assistance practices and disaster responses using geospatial big data and machine learning methods, aiming to address the SDG-10: Reduce Inequality and SDG-11: Sustainable Cities and Communities. Chapter 15 focuses on using GeoAI for infectious disease spread prediction to address the SDG-3: Good Health and Well-Being.
AI technologies are advancing rapidly, and new methods and use cases in GeoAI are constantly emerging. As GeoAI researchers, we should not purely hunt for latest AI technologies but should focus on addressing geographic problems and solving grand challenges facing our society as well as achieving sustainable development goals. We also need research effort toward the development of responsible, unbiased, explainable and interpretable GeoAI models to support geographic knowledge discovery and beyond. This GeoAI Handbook was completed in the middle of 2023. While it cannot summarize all GeoAI research in this one handbook, it provides a snapshot of current GeoAI research landscape and helps stimulate future studies in the coming years.
Greetings! We are very glad to invite you to mark your calendar for joining the forthcoming Geospatial Data Science Speaker Series Spring 2024 events, which are hosted by the GeoDS lab in Geography and co-sponsored by the Data Science Institute @UW-Madison.
We will first have Dr. Amr Magdy, an Assistant Professor of Computer Science and Engineering and a co-founding faculty member of the Center for Geospatial Sciences at UC Riverside, visiting UW-Madison and will present “Scalable Spatial Data Science for Social Scientists” 12:00 p.m.-1 p.m., on February 13, 2024 (Tue), Science Hall 140. Pizza lunch and coffee will be provided in the events.
The American Association of Geographers (AAG) Fellows is a recognition and service program that applauds geographers who have made significant contributions to advancing geography. Congratulations to Professor Song Gao who was recently selected into the 2024 AAG Fellows!
Dr. Song Gao is an associate professor of geography and the director of the Geospatial Data Science Lab at the University of Wisconsin Madison. He has established himself as one of the thought leaders and highly cited scholars in the field of geospatial artificial intelligence (GeoAI) and was heavily involved in the geospatial modeling of the spread of COVID-19. He has successfully mentored young scholars and students in GIScience, offered workshops and webinars for the AAG and other organizations, and is an associate editor for AAG’s International Encyclopedia of Geography and International Journal of Geographical Information Science. Dr. Gao’s involvement with cutting-edge data science and AI techniques, his commitment to taking on and solving important challenges, and his enthusiasm for working with different international organizations make him a strong asset to the AAG.
The new “Handbook of Geospatial Artificial Intelligence” edited By Drs. Song Gao (University of Wisconsin-Madison), Yingjie Hu (University at Buffalo), and Wenwen Li (Arizona State University) is now published! Dr. Michael F. Goodchild (University of California-Santa Barbara) wrote a Foreword to provide a historic context and recent advances to help the reader to understand the significant shift in the geographic sciences with AI.
This comprehensive handbook covers Geospatial Artificial Intelligence (GeoAI), which is the integration of geospatial studies and AI technologies such as machine (deep) learning and knowledge graph. It explains key fundamental concepts, methods, models, and technologies of GeoAI, and discusses the recent advances, research tools, and applications that range from environmental observation and social sensing to natural disaster responses. As the first single volume on this fast-emerging domain, the GeoAI handbook is an excellent resource for educators, students, researchers, and practitioners utilizing GeoAI in fields such as information science, environment and natural resources, geosciences, geography, and beyond!
By Philipe A. Dias, Thomaz Kobayashi-Carvalhaes, Sarah Walters, Tyler Frazier, Carson Woody, Sreelekha Guggilam, Daniel Adams, Abhishek Potnis, Dalton Lunga
We cannot wait to take our AAG 2024 GeoAI Symposium to Hawaii next year! Collaborating with 40+ colleagues across multiple continents, we have put together a series of paper and panel sessions. In the past year, we have been so excited to witness the rapid and continued growth of GeoAI, the advances in its methods and cross-domain applications. This year’s symposium will highlight these advances and will also include critical discussions on the issues of GeoAI and the societal challenges in its use in science and everyday life.
We welcome you to join us to present your papers, co-organize sessions, and serve as a panelist in our symposium. Your participation is key to helping us expand this exciting research community! If you have any questions, please feel free to reach out to the symposium’s lead organizers. The CFP can be found in the attachment.
AAG 2024 GeoAI Symposium organizing team
Lead Organizers: Wenwen Li, Arizona State University Yingjie Hu, University at Buffalo Song Gao, University of Wisconsin, Madison Budhu Bhaduri, Oak Ridge National Laboratory Orhun Aydin, Saint Louis University Shawn Newsam, University of California, Merced Samantha T. Arundel, United States Geological Survey Gengchen Mai, University of Georgia Krzysztof Janowicz, University of Vienna & University of California, Santa Barbara
GeoAI and Deep Learning Symposium: GeoAI for Science and the Science of GeoAI (Panel discussion session; in-person session; The organizing team)
GeoAI and Deep Learning Symposium: GeoAI Foundation Models (Panel discussion session; in-person session; The organizing team)
GeoAI and Deep Learning Symposium: GeoAI for Feature Detection and Recognition (Paper session; In-person session; Contact: Sam Arundel, US Geological Survey; Co-organizer: Wenwen Li, Arizona State University)
GeoAI and Deep Learning Symposium: GeoAI for Spatial Analytics and Modeling (Paper session; In-person session; Contact: Di Zhu, University of Minnesota; Co-organizers: Guofeng Cao, University of Colorado, Boulder; Song Gao, University of Wisconsin, Madison; Chaogui Kang, China University of GeoSciences)
GeoAI and Deep Learning Symposium: Emerging Geo-Data Applications in Human Mobility Analysis (Paper session; In-person session; Contact: Xiao Li, University of Oxford; Co-organizers: Xiao Huang, University of Arkansas, Haowen Xu, Oak Ridge National Laboratory, Yuhao Kang, University of South Carolina; Di Zhu, University of Minnesota)
GeoAI and Deep Learning Symposium: GeoAI for Ecosystem Conservation and and Sustainable Geodesign (Contact: Orhun Aydin, Saint Louis University; Somayeh Dodge, University of California Santa Barbara)
GeoAI and Deep Learning Symposium: GeoAI for Disaster Resilience I (Paper session; In-person session; Contact Bing Zhou, Texas A&M University. Co-organizers: Lei Zou, Texas A&M University;Yingjie Hu, University at Buffalo; Marcela Suárez, Penn State University, Yi Qiang, University of South Florida; Manzhu Yu, Penn State University; Morteza Karimzadeh, University of Colorado Boulder)
GeoAI and Deep Learning Symposium: Urban Visual Intelligence (Paper session; In-person session; Contact: Fan Zhang, Peking University, Co-organizer: Yuhao Kang, University of South Carolina; Filip Biljecki, National University of Singapore)
GeoAI and Deep Learning Symposium: Spatially Explicit Machine Learning and Artificial Intelligence (Paper session; In-person session; Contact: Gengchen Mai, University of Georgia; Co-organizers:Angela Yao, University of Georgia; Yao-Yi Chiang, University of Minnesota-Twin Cities; Krzysztof Janowicz, University of Vienna & UC Santa Barbara; Zhangyu Wang, University of California Santa Barbara; Di Zhu, University of Minnesota-Twin Cities)
GeoAI and Deep Learning Symposium: GeoAI for Cartography and Mapping (Paper session; In-person session; Contact: Yao-Yi Chiang, University of Minnesota-Twin Cities; Co-organizer: Jina Kim, University of Minnesota)
GeoAI and Deep Learning Symposium: Responsible GeoAI: Privacy, Fairness, and Interpretability in Spatial Data Science (Paper session; In-person session; Contact: Hongyu Zhang, McGill University; Co-organizers: Yue Lin, University of Chicago; Jinmeng Rao, Mineral Earth Sciences, Alphabet Inc.; Junghwan Kim, Virginia Tech; Song Gao, University of Wisconsin – Madison)
GeoAI and Deep Learning Symposium: GeoAI for Sustainable and Computational Agriculture (Paper session; In-person session; Contact: Jinmeng Rao, Mineral Earth Sciences, Alphabet Inc.; Co-organizers: Yuchi Ma, Stanford University; Jiahao Fan, University of Wisconsin-Madison; Hongxu Ma, Mineral Earth Sciences, Alphabet Inc.; Gengchen Mai, University of Georgia; Di Zhu, University of Minnesota, Twin Cities)
GeoAI and Deep Learning Symposium: Human-centered Geospatial Data Science (Paper session; In-person session; Contact: Yuhao Kang, University of South Carolina; Co-organizers: Filip Biljecki, National University of Singapore)
GeoAI and Deep Learning Symposium: GeoAI and Social Sensing for Human-Pandemic Dynamics (Paper session; In-person session; Contact: Binbin Lin, Texas A&M University, Mingzheng Yang, Texas A&M University; Co-organizers: Lei Zou, Texas A&M University)
GeoAI and Deep Learning Symposium: GeoHealth Data Science (Paper session; In-person session; Contact: Jiannan Cai, The Chinese University of Hong Kong; Co-organizer: Mei-Po Kwan, The Chinese University of Hong Kong)
GeoAI and Deep Learning Symposium: AI for Earth Observation (Paper session; In-person session; Contact: Bo Peng, PAII, Ping An U.S. Research Lab; Co-organizer: Chenxi Lin, PAII, Ping An U.S. Research Lab ; Beth Tellman, University of Arizona; Bandana Kar, U.S. Department of Energy; Lexie Yang, Oak Ridge National Laboratory; Yanghui Kang, University of California, Berkeley; Qunying Huang, University of Wisconsin-Madison; Di Zhu, University of Minnesota, Twin Cities)
GeoAI and Deep Learning Symposium: Characterization of Place and Human Patterns of Life (Paper session; In-person session; Contact: Junchuan Fan,Oak Ridge National Laboratory; Co-organizer: Joon-Seok Kim, Oak Ridge National Laboratory; Licia Amichi, Oak Ridge National Laboratory)
To present your research in one of these sessions, please register and submit your abstract at https://aag.secure-platform.com/aag2024/. When you receive confirmation of your submission, please forward your confirmation email to the session organizers by Nov. 16, 2023.
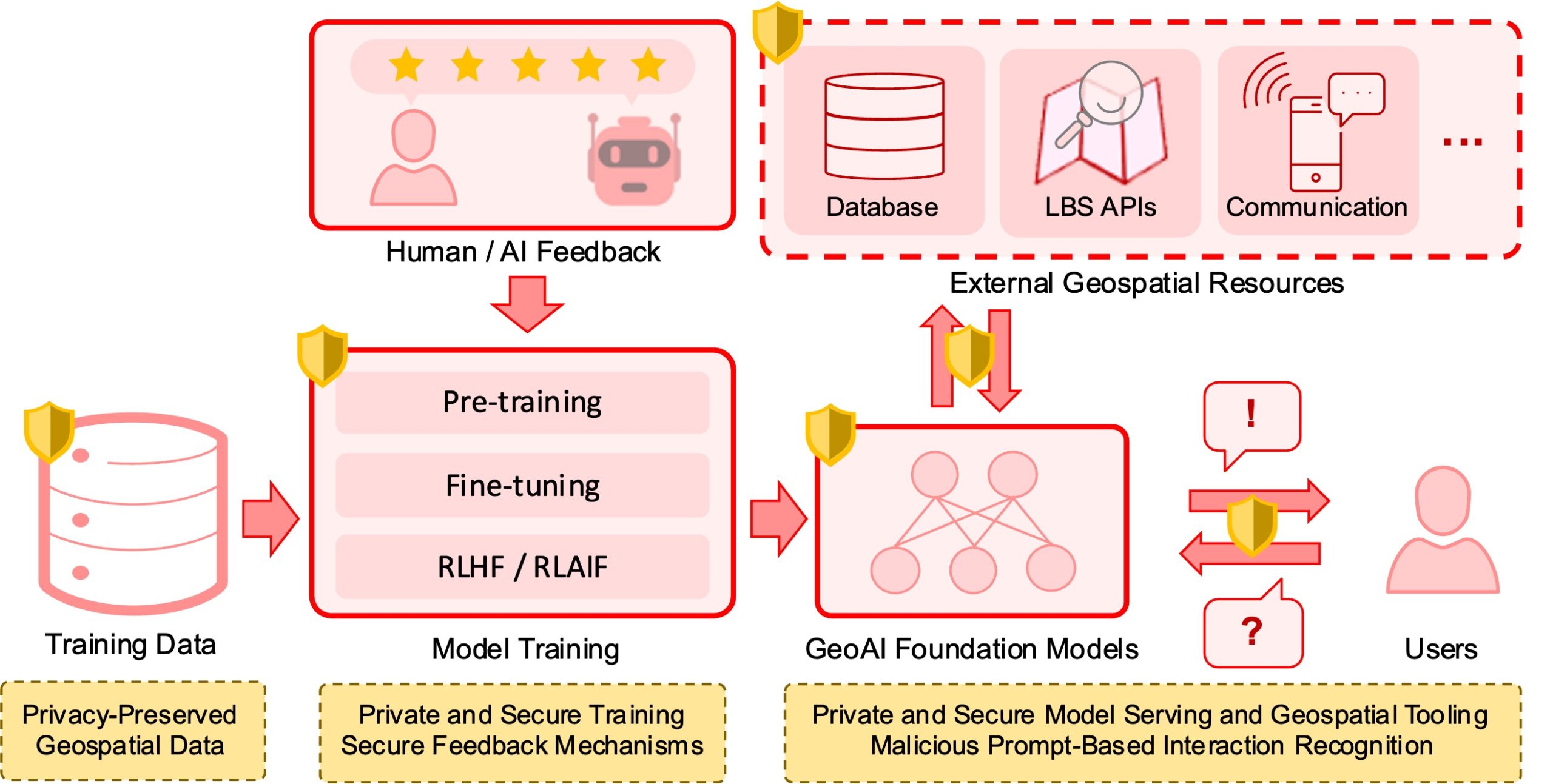
Abstract: In recent years we have seen substantial advances in foundation models for artificial intelligence, including language, vision, and multimodal models. Recent studies have highlighted the potential of using foundation models in geospatial artificial intelligence, known as GeoAI Foundation Models or Geo-Foundation Models, for geographic question answering, remote sensing image understanding, map generation, and location-based services, among others. However, the development and application of GeoAI foundation models can pose serious privacy and security risks, which have not been fully discussed or addressed to date. This paper introduces the potential privacy and security risks throughout the lifecycle of GeoAI foundation models and proposes a comprehensive blueprint for preventative and control strategies. Through this vision paper, we hope to draw the attention of researchers and policymakers in geospatial domains to these privacy and security risks inherent in GeoAI foundation models and advocate for the development of privacy-preserving and secure GeoAI foundation models.
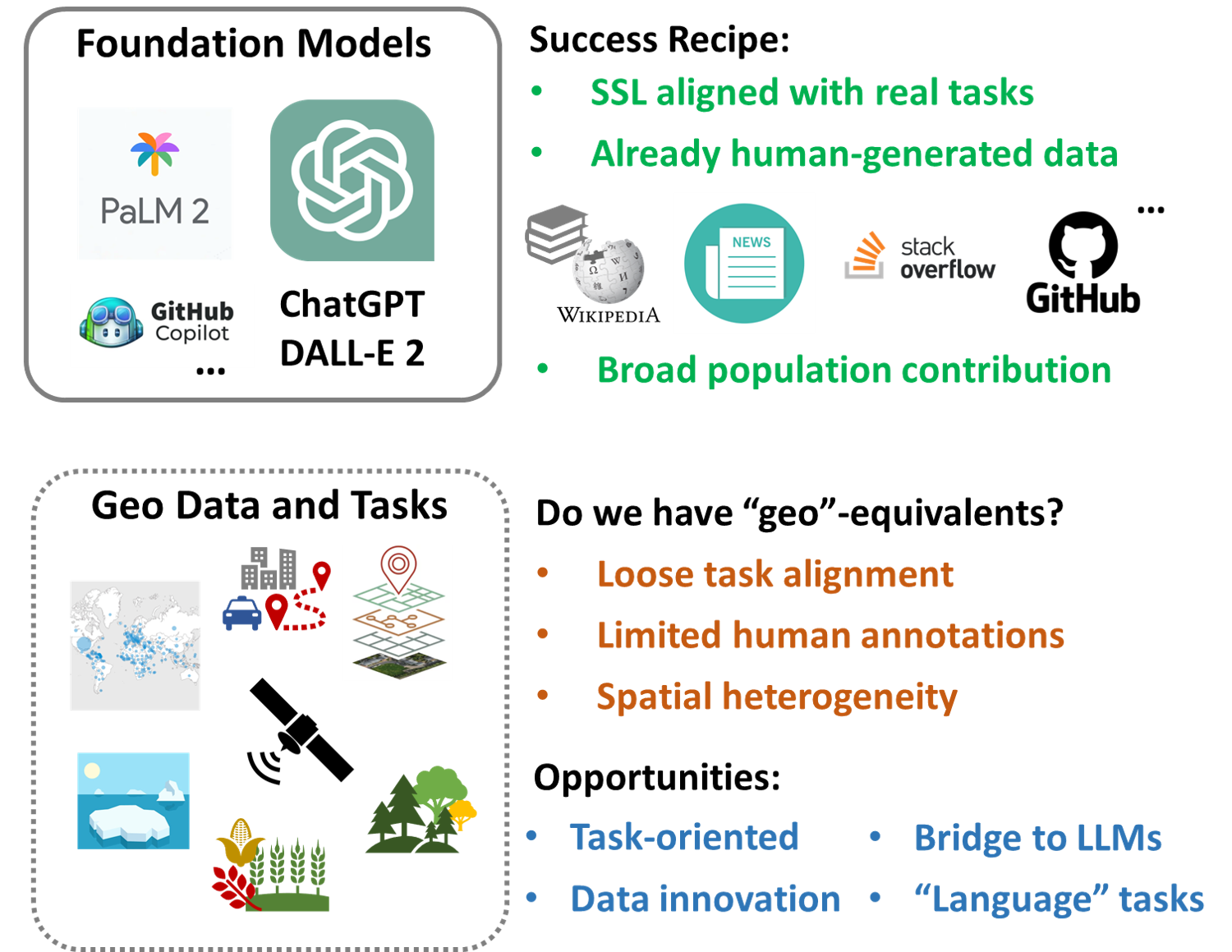
Abstract: With the recent rapid advances of revolutionary AI models such as ChatGPT, foundation models have become a main topic for the discussion of future AI. Despite the excitement, the success is still limited to specific types of tasks. Particularly, ChatGPT and similar foundation models have unique characteristics that are difficult to replicate for most geospatial tasks. This paper envisions several major challenges and opportunities in the creation of geospatial foundation (geo-foundation) models, as well as potential future adoption scenarios. We also expect that a major success story is necessary for geo-foundation models to take off in the long term.
Nick Ruktanonchai (Principal Investigator) ,Virginia Tech
Shengjie Lai (Co-PI) , University of Southampton
Omar Saucedo (Co-PI) , Virginia Tech
Corrine Ruktanonchai (Co-PI) , Virginia Tech
Song Gao (Co-PI), University of Wisconsin-Madison
Robert Holt (Co-PI) , University of Florida
Nicholas Kortessis (Co-PI), Wake Forest University
ABSTRACT
When people change where, when, and why they travel, there are effects on infectious diseases. People?s movements determine who is at risk of the disease and whether new cases are counted by local public health agencies. For example, during the COVID-19 pandemic, people?s movements changed drastically and, in addition to COVID-19, influenza and Lyme disease cases also dropped nationwide. These drops in cases may be because people spent less time in high risk areas, or simply because people traveled to healthcare facilities less frequently, and so fewer cases are reported. Distinguishing between these alternatives is critical for understanding disease control and predicting disease spread, but is made difficult when travel patterns change dramatically. This problem is especially challenging because communities may modify travel patterns in response to local disease, which can, in turn, change how diseases spread in communities and how public health monitors disease. To determine the cause of case reductions as human movements changed, the Investigators will develop new mathematical models that account for the ways travel impacts both risk and detection, using data from mobile phones to inform transmission risk and using local surveys to inform underdetection rates. By developing this new collection of models, the Investigators will better understand how transmission and detection of various non-COVID-19 infections changed throughout the pandemic, recognize how this depends on the biology of the disease being considered, and predict how case numbers may change during future periods of significant community-level changes in travel.
Community-level travel patterns have multifactorial effects on the dynamics of any infectious disease. Major changes to travel patterns affect both transmission, as people spend more or less time in high-risk places, and detection, as people change their propensity to visit healthcare facilities. These factors also influence individual behaviour, because local increases in reported cases can cause people to change their travel further. This creates critically important feedback loops between transmission, detection, and travel. Depending on the interactions between these factors, changes to travel or transmission could lead to undercounting of cases or a harmful population-level response that leads to communities being exposed to more infections. As changes in community-level travel patterns become more likely with global factors such as climate change and emerging infectious disease threats, it becomes increasingly important for models to integrate their effects on both detection and transmission. The project addresses this need by developing novel models that account for the ways in which travel can simultaneously affect both transmission and detection, and be affected by reported and perceived disease risk. The Investigators will combine the models with mobility data obtained from SafeGraph and use local surveys to inform underdetection rates of key notifiable diseases across the New River Valley Health District of Virginia, and to develop a framework for predicting transmission and detection changes during future large-scale changes in travel. Central Appalachia is a key region for this work, as it experiences relatively high incidence of respiratory and Lyme diseases, and intervention adherence was especially low during the later stages of the COVID-19 pandemic.
This project is jointly funded by the Division of Mathematical Sciences (DMS) in the Directorate of Mathematical and Physical Sciences (MPS) and the Division of Social and Economic Sciences (SES) in the Directorate of Social, Behavioral and Economic Sciences (SBE).
The 12th International Conference on Geographic Information Science (GIScience 2023), which is a flagship conference in the field of GIScience, will be held 12 – 15th September, 2023. Leeds, UK. GeoDS lab members have two papers accepted as oral presentations.
Please join us in congratulating our GeoDS lab’s PhD students and undergraduate students’ recent awards and achievements!
Yuhao Kang:
2023 Waldo-Tobler Young Researcher Award in GIScience, by the Austrian Academy of Sciences (ÖAW) Commission for GIScience to encourage scientific advancement in the disciplines of Geoinformatics and/or Geographic Information Science.
Recently, Prof. Song Gao received the 2023 Emerging Scholar Award by the American Association of Geographers (AAG) Spatial Analysis and Modeling (SAM) Specialty Group.
The AAG SAM Emerging Scholar Award The emerging scholar award honors early- to mid-career scholars who have made significant contributions to education and research initiatives that are congruent with the mission of AAG-SAM. The candidates must have received their Ph.D. within the last 10 years and must be a member of the AAG-SAM at the time that the person is being nominated.
Organizers: Rafael Pires de Lima, rlima@colorado.edu, University of Colorado Boulder; Co-organizers: Morteza Karimzadeh, University of Colorado Boulder, Guofeng Cao, University of Colorado Boulder, Andong Ma, University of Colorado Boulder
Organizers: Yingjie Hu, Song Gao, Wenwen Li, Dalton Lunga, Orhun Aydin, and Shawn Newsame
Panelists: Michael Goodchild, University of California Santa Barbara, A-Xing Zhu, University of Wisconsin, Madison, May Yuan, University of Texas Dallas, Orhun Aydin, Saint Louis University, Budhendra Bhaduri, Oak Ridge National Laboratory)
Organizers: Xiao Li, xiao.li@ouce.ox.ac.uk, University of Oxford; Co-organizers: Xiao Huang, University of Arkansas, Haowen Xu, Oak Ridge National Laboratory, Yuhao Kang, University of Wisconsin, Madison
Organizers: Gengchen Mai, gengchen.mai@gmail.com, University of Georgia; Co-organizers:Angela Yao, University of Georgia; Yao-Yi Chiang, University of Minnesota-Twin Cities; Zhangyu Wang, University of California Santa Barbara
Organizers: Gengchen Mai, gengchen.mai@gmail.com, University of Georgia; Co-organizers:Angela Yao, University of Georgia; Yao-Yi Chiang, University of Minnesota-Twin Cities; Zhangyu Wang, University of California Santa Barbara
Organizers: Gengchen Mai, gengchen.mai@gmail.com, University of Georgia; Co-organizers:Angela Yao, University of Georgia; Yao-Yi Chiang, University of Minnesota-Twin Cities; Zhangyu Wang, University of California Santa Barbara
Organizers: Di Zhu, dizhu@umn.edu, University of Minnesota; Co-organizer: Guofeng Cao, University of Colorado, Boulder; Song Gao, University of Wisconsin, Madison
Organizers: Bing Zhou, spgbarrett@tamu.edu, Texas A&M University. Co-organizers: Lei Zou, Texas A&M University;Yingjie Hu, University at Buffalo; Marcela Suárez, Penn State University
Organizers: Yuhao Kang, yuhao.kang@wisc.edu, University of Wisconsin, Madison; Co-organizer: Fan Zhang, cefzhang@ust.hk, Hong Kong University of Science and Technology
Greetings! I am very glad to invite you to mark your calendar for joining the forthcoming Geospatial Data Science Speaker Series Spring 2023 events, which are hosted by the GeoDS lab in Geography and co-sponsored by the Data Science Institute, UniverCity Alliance, and GISPP @UW-Madison. We will have Dr. Filip Biljecki, the Director of Urban Analytics Lab from the National University of Singapore visit UW-Madison 11:45 a.m.-1 p.m., on March 28, 2023 (Tue), Science Hall 110and Dr. Fabio Duarte from the MIT Senseable City Lab on April 13 (Thur), Science Hall 140. Pizza lunch and coffee will be provided in the events.
Recently, Prof. Song Gao was invited to join the Associate Editors team ofInternational Journal of Geographical Information Science(IJGIS), which is a flagship international journal for publishing geographic information systems/science related research. Dr. Gao’s service term starts from January 1st, 2023.
Aims and Scope
The aim of International Journal of Geographical Information Science is to provide a forum for the exchange of original ideas, approaches, methods and experiences in the field of GIScience.
International Journal of Geographical Information Science covers the following topics:
Innovations and novel applications of GIScience in natural resources, social systems and the built environment
Relevant developments in computer science, cartography, surveying, geography, and engineering
Fundamental and computational issues of geographic information
The design, implementation and use of geographical information for monitoring, prediction and decision making
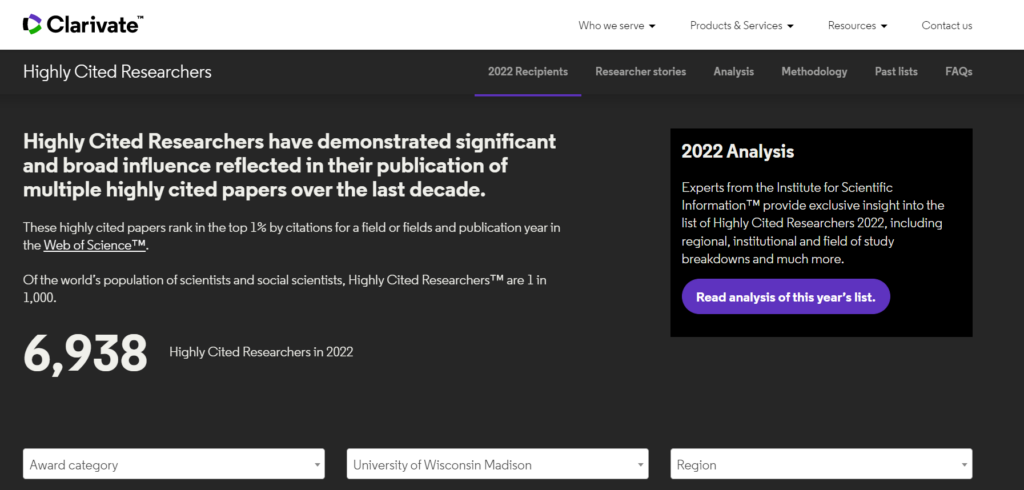
Prof. Song Gao is on this year’s list of Global Highly Cited Researchers List of 2022 and the only scholar from UW-Madison listed in the category of Social Sciences. Kudos to his colleagues, students, and mentors!
On November 15 2022, Clarivate revealed its 2022 list of Highly Cited Researchers™ – individuals at universities, research institutes and commercial organizations who have demonstrated a disproportionate level of significant and broad influence in their field or fields of research. The methodology draws on data from the Web of Science™ citation index, together with analysis performed by bibliometric experts and data scientists at the Institute for Scientific Information (ISI)™ at Clarivate. ISI analysts have awarded Highly Cited Researcher 2022 designations to 6,938 researchers from across the globe who demonstrated significant influence in their chosen field or fields over the last decade. ISI analyzed all papers published and cited between 2011 and 2021, determining which authors ranked in thetop 1% of cited papers in each field. The list is truly global, spanning 69 countries or regions and spread across a diverse range of research fields in the sciences and social sciences.
Prof. Gao is also on the list oftop 2% highly cited scientists based on Stanford University’s analysis of Scopus data provided by Elsevier.
During the week of November 1-4, 2022, all the GeoDS lab members were traveling to two academic conferences: ACM SIGSPATIAL 2022 and AutoCarto 2022.
Prof. Song Gao, Wen Ye (undergraduate student), Yunlei Liang (PhD student), Yuhan Ji (PhD student), Jiawei Zhu (visiting PhD student), and Jinmeng Rao (PhD Candidate), presented at the 30th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2022) in Seattle, Washington, USA.
We published two short research papers in the main conference, three workshop full papers, and won a “Best Paper Award”.
In addition, Yuhao Kang (PhD Candidate) and Jake Kruse (PhD Student) presented two short papers in the AutoCarto 2022, the 24th International Research Symposium on Cartography and GIScience.
A Review and Synthesis of Recent GeoAI Research for Cartography: Methods, Applications, and Ethics. Yuhao Kang, Song Gao, Robert Roth (2022)
Interactive Web Mapping for Multi-Criteria Assessment of Redistricting Plans.Jacob Kruse, Song Gao, Yuhan Ji and Kenneth Mayer (2022)
This summer, Yunlei, a Ph.D. student from the GeoDS lab, was selected for a Data Science Fellowship program provided by Correlation One. It is a unique fellowship program designed for Ph.D./Master’s students looking to transition from academia into data science roles with a 5% acceptance rate of over 6,000 global applicants. Here she shares her experience with this valuable educational opportunity:
Through the 7-week program, I was involved in various formats of Data Science learning. Every Saturday, I attended online lectures built on real-world cases and delivered by lecturers from universities like Carnegie Mellon, Duke, & Columbia. We learned skills such as exploratory data analysis (EDA), SQL basics, and statistical testing. I also had the opportunity to connect with an assigned mentor from the industry, and career success coaches to improve professional development. Most importantly, I collaborated with a team of 6 with various backgrounds to develop a capstone project using machine learning and data science skills we learned through the lectures.
I greatly appreciate this opportunity to learn from people who are passionate and enthusiastic about data and to expand my network. If you are interested, here is the link to the program: https://www.correlation-one.com/data-science-for-all-women
As a young scholar in the field of GIScience, Dr. Gao’s scholarly output constitutes an impressive list of well-cited publications that are proving to furnish innovative ideas and methods impacting the theory and practice of GIScience within the interface of geospatial artificial intelligence (particularly machine learning), big spatial data, and a more humanistic oriented place-based GIS. In addition, Dr. Gao has secured substantial sums of external funding to support his research, and has begun filling GIScience Community leadership roles. The UCGIS Research Awards Review Committee assesses that Dr. Gao has achieved a national and international GIScience profile and reputation that far exceeds expectations for a junior scholar.
The UCGIS Early-Mid Career Research Award is to celebrate an outstanding early-mid career research record of innovative ideas or methods that lead to research impacts on the theory and/or practice of GIScience or geographic information technology.
UCGIS will honor Song Gao and other award recipients as part of its Symposium 2022 programming activities.
Please join us congratulating our junior student Wen (Wendy) Ye, who is currently an undergraduate triple-majoring in computer science, data science, and statistics as well as a research assistant in the GeoDS Lab under Prof. Song Gao’s mentorship, just got the UW-Madison “Hilldale Undergraduate/Faculty Research Fellowship” and will be awarded in the 2022 Chancellor’s Undergraduate Awards Ceremony!
The awarded research project is: Understanding spatial inequality to health care access in Wisconsin through deep learning-based network analysis.